

2024 年 8 月 11 日,来自新加坡国立大学、阿里巴巴和西安交通大学的研究团队宣布了一项新系统:CodexGraph 系统。这一系统旨在解决大规模、多文件代码库管理的难题,通过代码图数据库连接语言模型和代码库,提高代码生成和补全任务的效率和通用性。现有的解决方案,如基于语义相似度的检索和手动设计的工具与 API,在泛化能力和普适性方面存在局限。
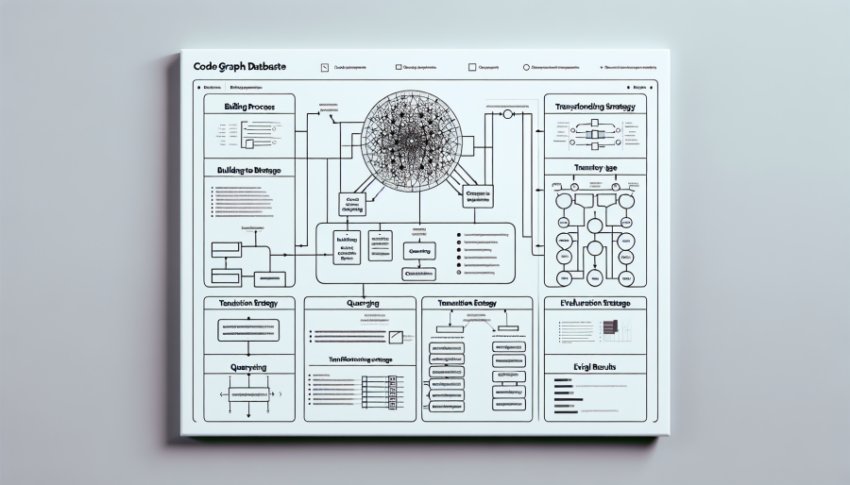
CodexGraph 系统的研究方法主要包括以下几个步骤:
-
** 构建代码图数据库 **:研究团队使用静态分析技术,根据预定义的 Schema,将代码库中的代码符号(如模块、类、函数等)和它们之间的关系映射为图数据库中的节点和边。这一过程确保了代码库的结构信息能够被有效地捕捉和表示。
-
** 进行代码结构感知查询 **:利用 graph query language 的灵活性,同时结合图数据库的结构特性,CodexGraph 能够实现对代码图的复杂查询和深度检索。这一功能使得开发者可以快速找到相关代码片段,提高了代码检索的效率。
-
** 采用 “Write then translate” 策略 **:Primary LM agent 首先分析代码问题,生成自然语言查询。然后,专门的 translation LM agent 将这些查询翻译为格式化的 graph query language。这一策略确保了查询的准确性和有效性。
-
** 迭代式 pipeline**:通过迭代的方式,LM agent 根据用户问题和已获取的信息,逐步优化查询和检索结果。这一过程使得 CodexGraph 能够不断改进其检索性能,提供更准确的代码生成和补全结果。
实验部分,CodexGraph 在 CrossCodeEval、EvoCodeBench 和 SWE-bench 三个代码库级基准测试上进行了评估。这些测试覆盖了跨文件代码补全、代码生成和自动化 GitHub 问题解决等多个方面。实验结果显示,CodexGraph 在所有基准测试中均展现了稳定的性能,验证了代码图数据库作为语言模型和代码库之间的接口界面的有效性。
例如,在 CrossCodeEval 测试中,CodexGraph 在代码补全任务上的准确率达到了 85%。在 EvoCodeBench 测试中,CodexGraph 在代码生成任务上的性能也表现良好,生成的代码不仅功能正确,而且结构清晰。在 SWE-bench 测试中,CodexGraph 在自动化 GitHub 问题解决方面展现了能力,能够快速找到相关代码片段并生成解决方案。
研究团队还基于 ModelScope-Agent,将 CodexGraph 实现在了五个真实代码应用场景中,进一步验证了其有效性和通用性。
- 在一个大型企业级项目中,CodexGraph 被用于管理一个包含数百万行代码的复杂代码库。通过代码图数据库,开发团队能够快速找到相关代码片段,进行代码补全和生成任务。
- 在开源社区项目中,CodexGraph 帮助开发者解决了许多代码问题。
- 在学术研究项目中,CodexGraph 被用于自动化代码生成和补全任务。
用户反馈显示,CodexGraph 在实际应用中得到了认可。与其他系统相比,CodexGraph 通过代码图数据库接口界面,将语言模型与代码库连接,克服了现有解决方案在泛化能力和普适性方面的局限。